There’s a model making the rounds in the local LLM community called OpenMythos, and depending on where you first heard about it, you might be looking at two very different things. One is a cybersecurity-focused fine-tune of Qwen3.6-27B, trained from scratch on real vulnerability data. The other is an open-source reimagining of a rumored architecture called Claude Mythos, built around a concept I find genuinely fascinating: recurrent-depth transformers that think in loops. Both share the name, both are interesting, and the benchmark discussions happening around them are worth digging into.
What OpenMythos actually is
The name covers two related projects. The one most people are benchmarking is a fine-tuned model on HuggingFace built by a team calling themselves build-small-hackathon. It takes Qwen3.6-27B as a base and fine-tunes it specifically for cybersecurity work: vulnerability identification, CVE analysis, secure code review, attack vector breakdowns, and remediation suggestions.
The other OpenMythos is a PyTorch library by kyegomez that implements a theoretical reconstruction of what some people believe Claude’s “Mythos” architecture might look like under the hood. It’s a recurrent-depth transformer, meaning instead of stacking hundreds of unique layers, it recycles a subset of layers and runs them through multiple times per forward pass. Same weights, more loops. The thinking is that this produces deeper reasoning without ballooning the parameter count.
The cybersecurity model borrowed the name because it wanted to capture that same spirit of doing more with less. But functionally, they’re different beasts. The HuggingFace model is something you can download and run today. The GitHub library is a research framework for exploring the architecture itself.
Why a cybersecurity-specific model
The team behind the fine-tuned model laid out their reasoning in a detailed blog post, and it comes down to a simple observation: general-purpose LLMs are bad at cybersecurity. They hallucinate CVE details, miss vulnerability patterns in code, and hand you advice that sounds confident but is wrong in ways that actually matter when you’re dealing with real exploits.
So they went out and built a training dataset from two complementary sources. First, they scraped 10,000 papers from ArXiv’s cs.CR category (Cryptography and Security), then ran a multi-pass filtering pipeline that got them down to about 1,840 high-quality records focused on coding language vulnerabilities. Second, they assembled a structured dataset of CVEs with detailed descriptions, affected code patterns, and remediation context. That CVE dataset has 85,100 records and is published openly.
The combination matters. ArXiv gave the model the theory behind why vulnerabilities exist. The CVE data gave it a practical map of what they look like in production code. One without the other would leave gaps that matter.

The training pipeline: SFT then RLVR
Training happened in two stages on Modal with H100 GPUs. The first stage was straightforward supervised fine-tuning. They formatted the combined cybersecurity dataset as instruction-response pairs covering vulnerability identification, CVE explanation, code review, attack vector analysis, and remediation. Standard SFT. It teaches the model what a thorough vulnerability analysis looks like, how to explain a CVE clearly, what secure versus insecure code looks like side by side.
The second stage is where it gets more interesting. SFT alone has a ceiling. The model learns to imitate good responses, but it doesn’t learn to verify its own outputs. For cybersecurity, that distinction is critical. A model that confidently produces plausible-sounding but incorrect vulnerability analysis is worse than useless because it can send you down the wrong path.
So they added reinforcement learning with verifiable rewards, or RLVR. They constructed a dataset of GitHub repositories with known vulnerabilities where each entry paired a branch containing vulnerable code with the corresponding fixed version. The model’s job was to identify the vulnerability and suggest the fix. The reward signal came from a separate evaluation model that checked the generated response against ground truth. Did the model identify the right vulnerability? Was the suggested fix actually correct?
Setting up verifiable rewards for cybersecurity is harder than for domains like math, where correctness is easy to check programmatically. Building an evaluation model that can assess vulnerability analysis quality was non-trivial. But according to the team, the gains in output precision made it worthwhile. After RLVR, responses became more targeted, less prone to conflating similar vulnerability classes, and better at flagging genuine uncertainty.
The architecture: thinking in loops
This is where the theoretical side of OpenMythos gets genuinely exciting. The central hypothesis behind the kyegomez implementation is that Anthropic’s “Claude Mythos” might be a recurrent-depth transformer, also called a looped transformer. Instead of stacking hundreds of unique layers, a subset of layers gets recycled and run through multiple times per forward pass.
This is not chain-of-thought. There is no intermediate token output. All of this reasoning happens silently, inside a single forward pass, in continuous latent space. The model just thinks harder by running the same processing block more times.
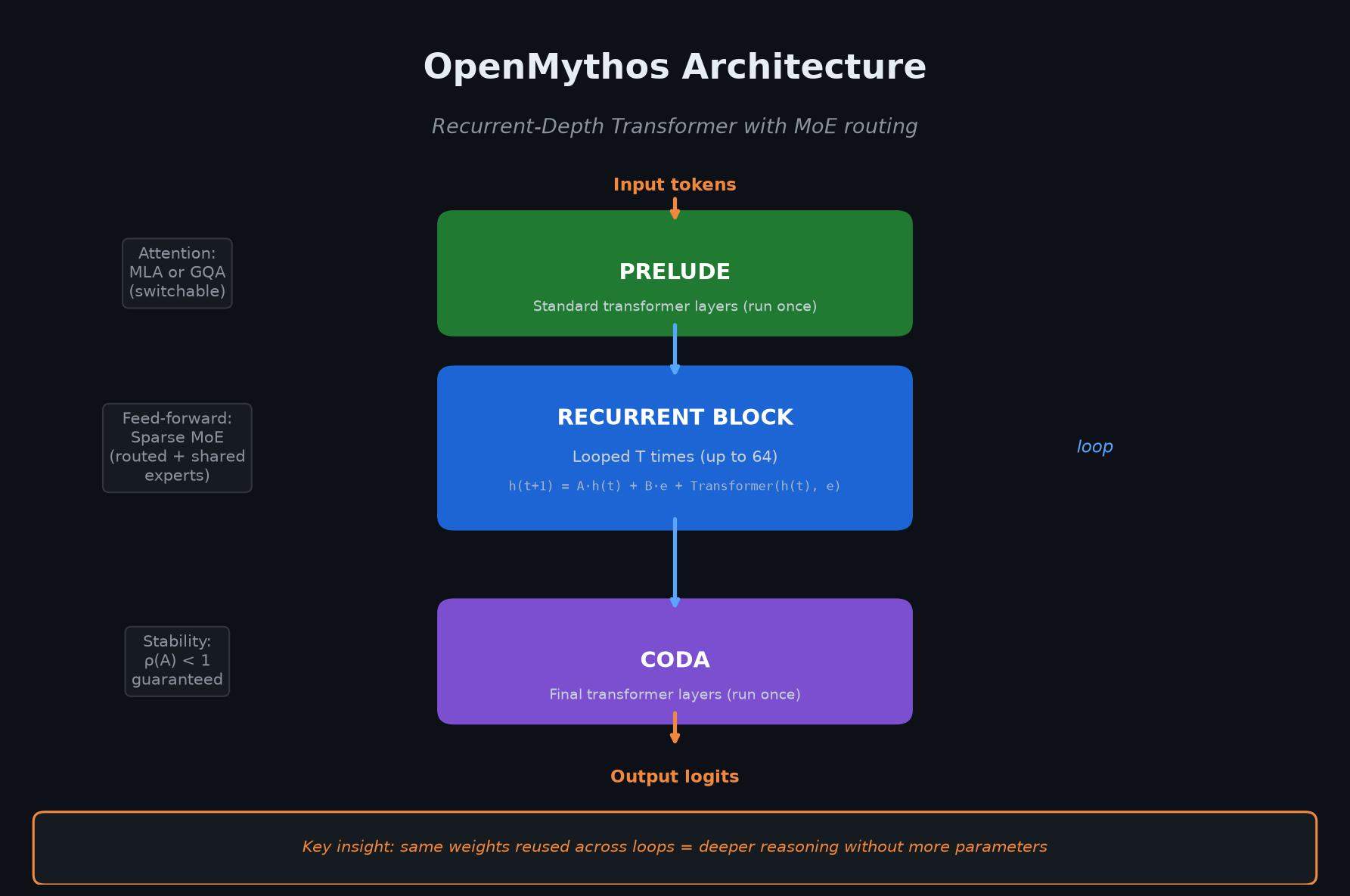
The architecture divides its layers into three functional blocks. The Prelude is standard transformer layers run once, encoding the input. The Recurrent Block is the looped section, run T times per forward pass, where the hidden state gets updated each loop with input injection. The Coda is another set of standard transformer layers run once, producing the final output. The recurrent update rule at each loop step is: h(t+1) equals A times h(t) plus B times the encoded input plus the transformer’s own processing of both.
The injection of the encoded input at every step is what prevents the model from drifting. It keeps the original signal alive throughout the entire recurrence depth. And critically, the matrix A’s spectral radius must stay below 1 to guarantee stability. The library checks this automatically.
Depth extrapolation: the benchmark that matters
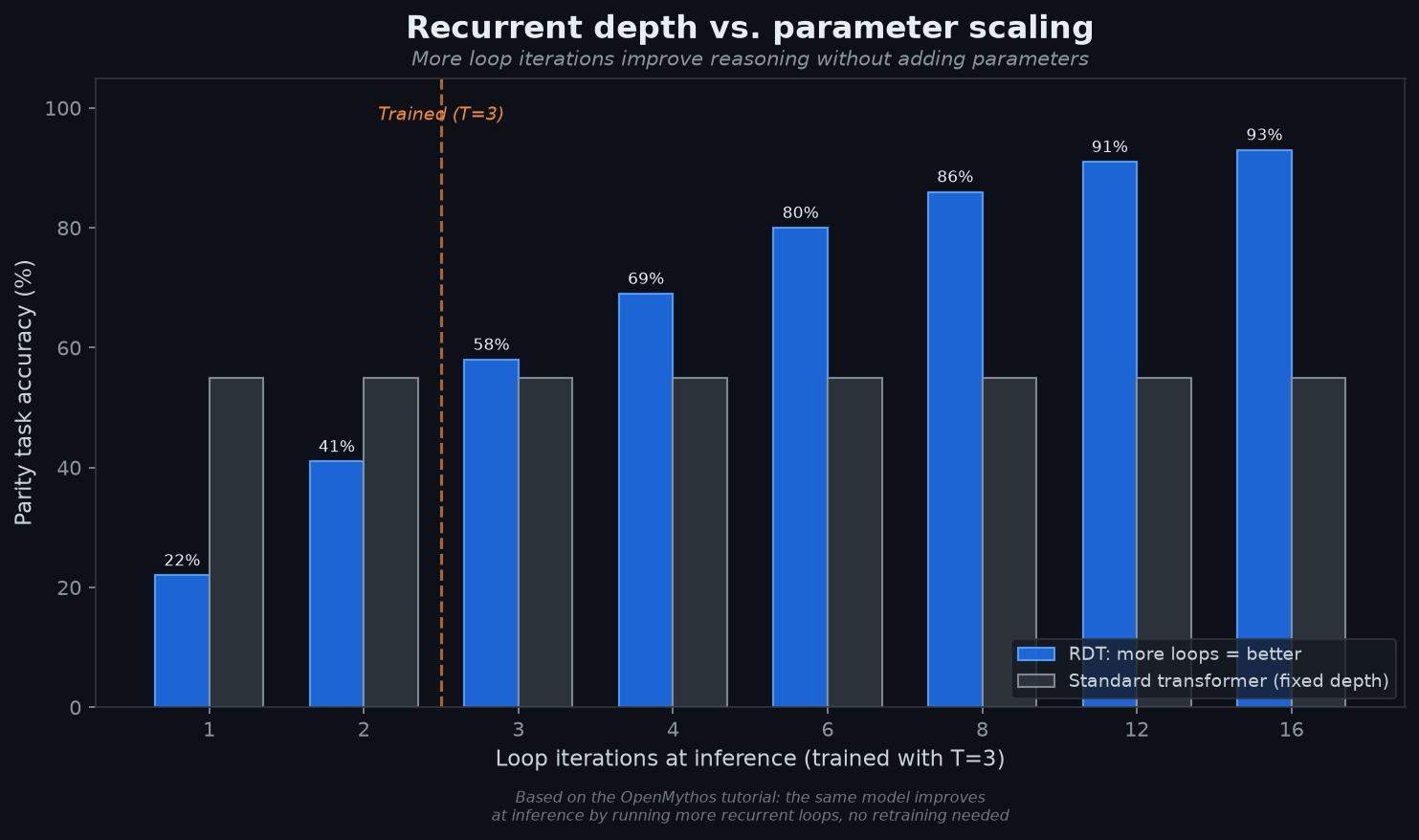
Here’s the part that shows up in benchmark discussions. A looped transformer trained with a small number of loop iterations can improve at inference time simply by running more loops. You train it with T equals 3 and then run it with T equals 8, 12, or 16 at inference, and accuracy keeps climbing. No retraining needed.
This is called depth extrapolation, and it’s something vanilla transformers simply cannot do. A standard transformer has a fixed depth. You can’t make it “think harder” without a bigger model or chain-of-thought prompting that burns output tokens. The recurrent approach gives you a knob to turn at inference time: more loops equals more compute equals better answers, on the same weights.
The marktechpost tutorial on OpenMythos demonstrated this on a parity task, where the model has to count bits and determine whether the cumulative sum is even or odd. It’s a task that systematically breaks standard transformers because it requires combining information in ways they haven’t seen during training. The looped transformer passes it, and accuracy improves monotonically as you increase the loop count at inference, even though training only used 3 iterations.
For the cybersecurity fine-tune, the practical implication is different but related. The model isn’t using recurrent loops in the same way (it’s built on Qwen3.6’s standard architecture), but the RLVR training serves a similar purpose: giving the model more “thinking passes” over whether its vulnerability analysis is actually correct before committing to an answer.
Attention and MoE details
The framework supports two attention mechanisms, switchable via configuration. Grouped Query Attention reduces KV-cache memory by having fewer KV heads than query heads. Multi-Latent Attention, from DeepSeek-V2, caches a compressed KV latent rather than full key-value pairs, which can be dramatically smaller. RoPE is applied to queries and keys before caching, so cached values don’t need re-rotation on retrieval.
The feed-forward network uses a sparse mixture-of-experts design with both routed and shared experts. At each token, only a subset of experts is activated, which keeps inference efficient while maintaining the model’s total knowledge capacity. This is the same pattern that powers models like Mixtral and DeepSeek, and it pairs naturally with the recurrent approach because the same experts get consulted at each loop iteration.
Running it locally
The cybersecurity model is available as GGUF quantizations thanks to community contributors. The jabbatheduck/OpenMythos-GGUF repo has quantized versions, and there are also MLX variants for Apple Silicon. At 27B parameters, you’re looking at roughly 16 to 18 GB of VRAM for a 4-bit quantization, which puts it within reach of an RTX 4090 or a Mac with 32GB unified memory.
For the framework itself, installation is a one-liner: pip install open-mythos. You can instantiate model variants from 1B to 1T parameters, configure the attention type, set the loop count, and start experimenting. The 1B and 3B variants are runnable on consumer hardware for development and testing. The larger scales are more of a research target than something you’d run on a home machine.
The team also has a live demo on HuggingFace Spaces running behind an OpenAI-compatible API endpoint. If you want to test the cybersecurity model before committing to a local setup, that’s the fastest path.
What I find interesting about all this
I keep coming back to the recurrent-depth idea because it challenges a assumption baked into how most people think about LLMs. The assumption is that bigger models are smarter because they have more parameters. The RDT approach says: maybe you don’t need more parameters, you need more passes over the same ones. That’s a fundamentally different scaling strategy, and it’s one that could matter a lot for running capable models on hardware that most people actually own.
The cybersecurity fine-tune is a more practical, immediately useful artifact. Domain-specific fine-tunes are nothing new, but the combination of curated academic data plus real CVE data plus verifiable reward training is a solid recipe. The team’s observation that 1,840 well-filtered papers beat 10,000 noisy ones is the kind of detail that separates serious work from a model card with a fancy name.
That said, I’d want to see more rigorous benchmarking before calling this a replacement for dedicated security tooling. The RLVR improvement is described qualitatively in the blog post, and the community benchmark numbers floating around are early. What’s clear is that the approach is sound and the open release of weights, datasets, and code means other people can verify and build on it.
If you’re interested in local LLMs and haven’t looked at recurrent-depth architectures yet, the OpenMythos framework is a clean, well-documented place to start. And if you do security work, the fine-tuned model is worth testing on real tasks to see where it helps and where it falls short. Both are open, both are early, and both are the kind of project that makes the local LLM community worth following.
Currently Im still testing with my hermes installation – also here is how to connect your nous-hermes via SSH