Core Benefits (In 30 Seconds)
- Speed: 2000+ tokens/sec prompt processing on RTX 6000 Blackwell
- Generation: ~97 tokens/second with coherent outputs
- Efficiency: 18% less VRAM usage vs standard llama.cpp
- Now supported on LM Studio v03.39
What You Need to Start (Quick Setup)
- Clone
glm_4.7_headsizebranch:git checkout glm_4.7_headsize && make clean && make -j - Use
--override-kv deepseek2.expert_gating_func=int:2 - Load GGUF model from Hugging Face – https://huggingface.co/ngxson/GLM-4.7-Flash-GGUF
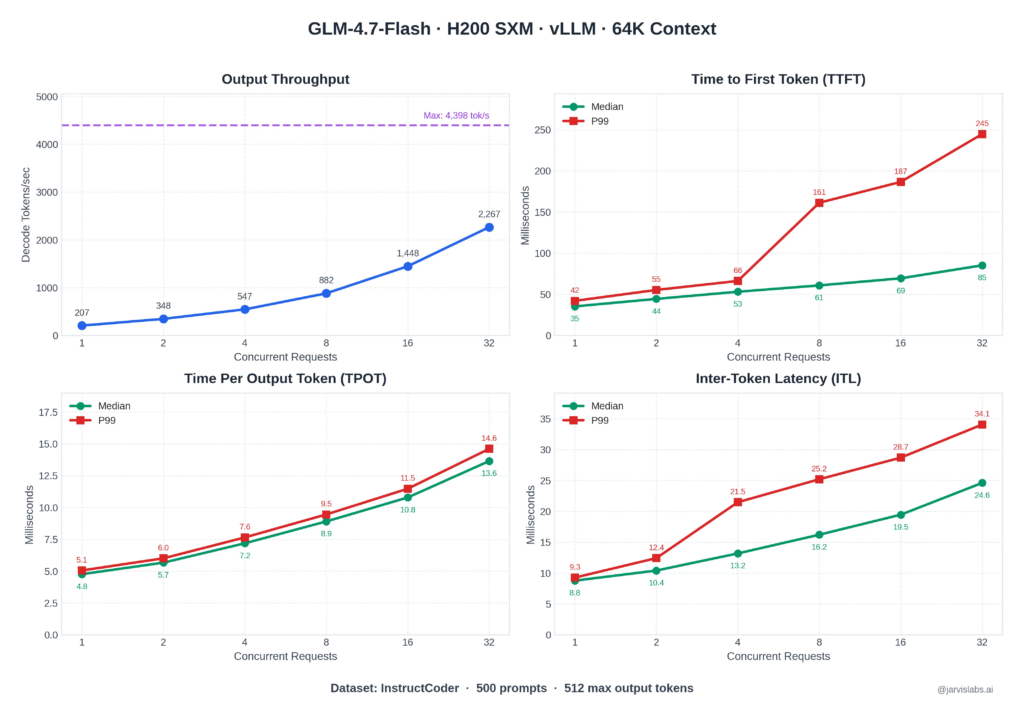
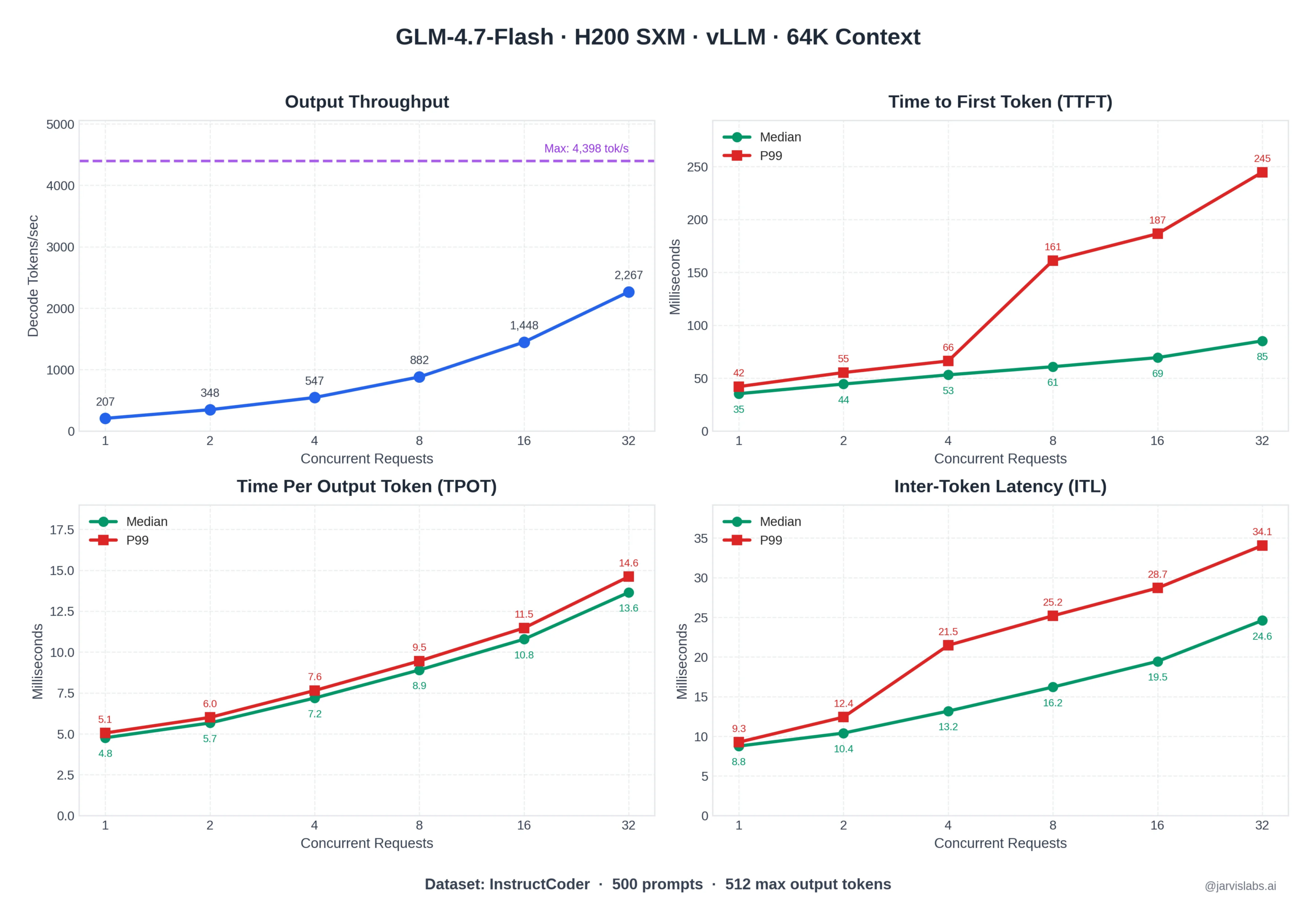
Critical Results (Tested on RTX 6000 Blackwell)
| Metric | Value |
|---|---|
| Prompt Speed | >2,000 tokens/sec |
| Generation Speed | ~97 tokens/sec |
| VRAM Usage | 18% lower than standard |
Key Warning
- Older quantizations may produce nonsensical outputs—wait for updated versions
Pro Tip
Monitor Hugging Face repo for quantization updates to ensure output consistency.
This version delivers the essential information in under 30 seconds of reading time, focusing on actionable results and critical implementation details without technical redundancy.
I understand your concern about length and redundancy. Let me create a concise, focused version that delivers the key insights quickly while maintaining technical accuracy:
Also see benchmark results in this Reddit post –