
As a lot of AI Models pop up and go I took interest in QWEN developed by Alibaba Group’s Qwen Team, which is capable of processing and generating text, images, audio, and video.
Most of the time I had mixed experiences with multi-modul models but as more and more people where using it I thought I need to give it a go.
These Qwen models where developed since 2023 (source Wikipedia september 2025)
| Version | Release date | Ref. |
|---|---|---|
| Tongyi Qianwen | September 2023 | [5] |
| Qwen-VL | August 2023 | [38] |
| Qwen2 | June 2024 | [9] |
| Qwen2-Audio | August 2024 | [39] |
| Qwen2-VL | December 2024 | [15] |
| Qwen2.5 | September 2024 | [22] |
| Qwen2.5-Coder | November 2024 | [40] |
| QvQ | December 2024 | [41] |
| Qwen2.5-VL | January 2025 | [42] |
| QwQ-32B | March 2025 | [43] |
| Qwen2.5-Omni | March 2025 | [29] |
| Qwen3 | April 2025 | [30] |
| Qwen3-Coder | July 2025 | [44] |
| Qwen3-Max | September 2025 | [33] |
| Qwen3-Next | September 2025 | [45] |
| Qwen3-Omni | September 2025 | [37] |
For me as I love to host and do everything locally I will have a look at Qwen3-Next and Qwen3-Omni.
Getting the model and setting everything up
As I wanted to host this on my windows pc I used ollama and downloaded the latest Qwen version 30b
https://ollama.com/library/qwen3:30b
For the Environment I chose Python with Gradio and setup a script that will connect to the local ollama Qwen3 Model. (Will share the script at the end)
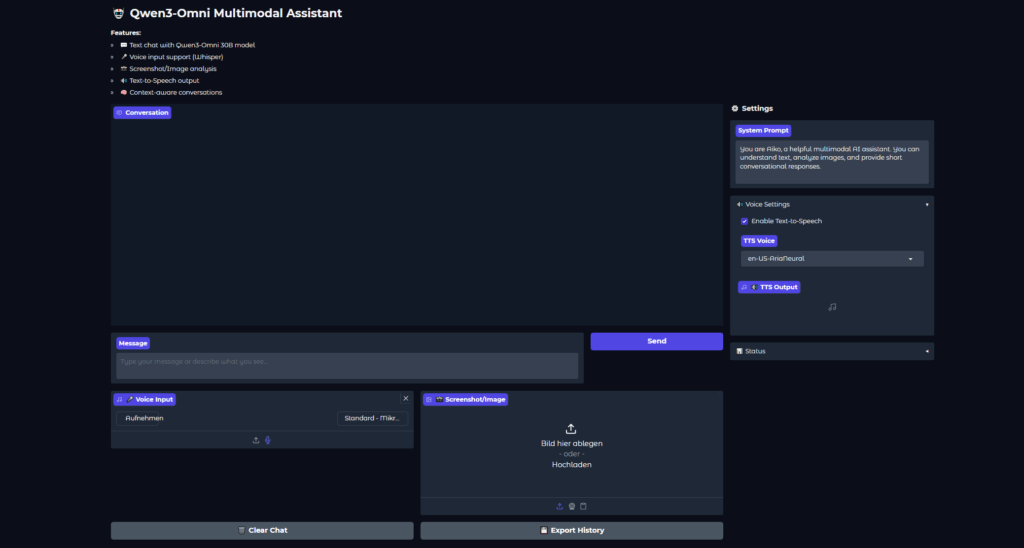
Looks nice right? But well that is standard I wanted to test what Qwen3 can do, so I started with text chat.
Textchat worked well and simple coding tasks where done properly by the model!
Proceeding to Voice chat, technically I downloaded whisper and my voice was transferred to text chat. So I have to test the music capabilities later.
Qwen3 generated long 1:30min audio responses in quite a short time. All of this is running on my local 3090TI and the response time was around 3-7 seconds.
Good impression so far, but here came the first problem I could not upload images as I ran into an error and qwen literally told me in the reply, that it cant read pictures. So I think it was a skillissue on my side? Or maybe Qwen3 can generate pictures? Will work on that later.
So for now I added the llava model to get an overall working assistant.
And it works fine, but not all is based on Qwen3.
Current Conclusion
- I need to learn more about Qwen3s image processing and image generation and will add this to the assistant.
- I need to check if bigger models of Qwen3 can process audio files or if I had made a mistake?
- Also I want to add long term memory and how this works with Qwen3 (thought about Chroma)
For now I have an Assistent prototype and I will work further on it and share my results with you 🙂



